Analysis of Random Forests and Deep Networks with Varying Sample Sizes
Team: NeuroData Design: RF/DN
- Program: Biomedical Engineering
- Course:
Project Description:
Random forests (RF) and deep networks (DN) are two of the primary machine learning methods in current literature, yet they are known to yield different levels of performance on different data modalities. In particular, RF (and other tree based ensemble methods) is one of the leading means for tabular data, while DNs are known to perform best on structured data. We wish to further explore and establish the conditions and domains in which each approach excels, particularly in the context of sample size. To address these issues, our team is analyzing the performance of these models across different settings using varying model parameters and architectures. For our data, we are focusing on well-known image, tabular, and audio datasets to observe performance from well-documented sources. For image data, we used CIFAR-10 with fixed sample sizes across different numbers of classes. For tabular data, we used OpenML-CC18, a collection of datasets representing a benchmark for machine learning analysis. For audio data, we used UrbanSound8k dataset across ten classes employing Mel-frequency cepstrum as a feature representation for audio. The goal of this project is to observe novel trends in model classification accuracy visible across a range of sample sizes.
https://github.com/NeuroDataDesign/rf-dn-paper
Project Photo:
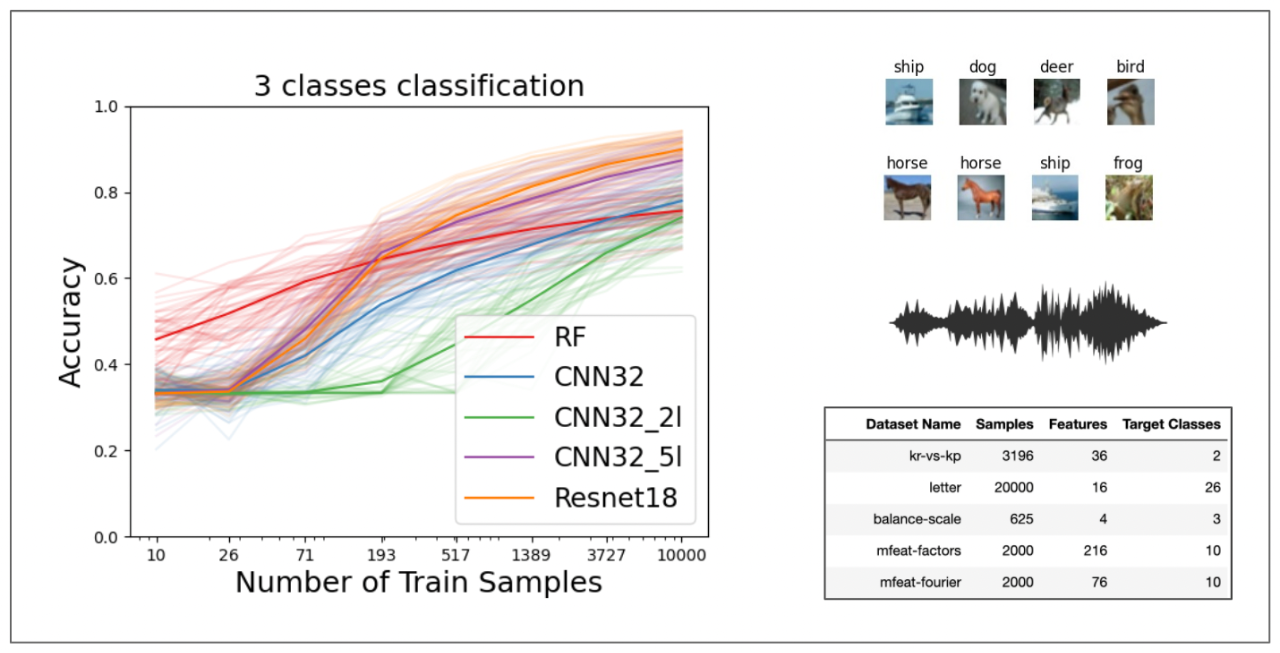
Preliminary Results and Dataset Overview
Student Team Members
- Michael Ainsworth
- Yu-Chung Peng
- Haoyin Xu
- Madi Kusmanov